3-D Smooth Zooming
Credits
- Ninad K. Jog(ninad@cs.umd.edu)
Algorithm Implementation and write-up.
- Bruce Chih-Lung Lin (cllin@cfar.umd.edu)
Devise new algorithms, identify optimizations.
Reviewers
- Greg Baratoff (baratoff@cfar.umd.edu)
- Claudio Esperanca (esperanc@umiacs.umd.edu)
- Read Reviews
Aim
This project aims at using novel data access methods and efficient screen-drawing
algorithms to facilitate rapid and flicker-free zooming of a 2-dimensional starfield
display. A starfield display uses dots to represent database items; the location and
color of each dot being a function of the attributes of the item.
Background
The exploration (browsing and querying) of large information spaces
(databases with a large number of items having several attributes) is greatly
facilitated if the items are represented as dots on a two-dimensional display,
with two of the attributes spread along the X and Y axes. A third attribute can be
displayed by color-coding the dots.
The project uses an existing FilmFinder application that embodies these
concepts. The X-axis shows the year of the film (ranges from 1920 to 1995)
and the Y-axis has the popularity (0-9). Each axis has a double-box slider
that changes the scale of the axis to perform a zoom - for example, using the x-axis
slider, you can zoom in to view films made between 1950 and 1995.
Zooming in causes the films' display rectangles to grow in size and also
move to different parts of the display.
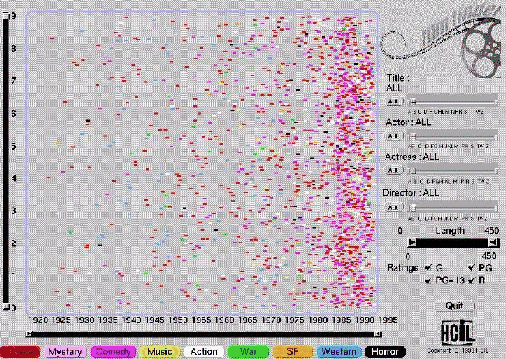
The third dimension is the length of each film, which is varied using a range
slider. The display itself is still 2-dimensional, but the same principles that are
used for the x and y ranges, apply.
The Challenge
For the zoom operation to appear continuous and smooth, three requirements have to be
met.
- The underlying data structure should facilitate rapid indexing
to reach the required items without wasteful comparisons.
- The display should be updated frequently enough for the motion to
appear continuous.
- The erase and redraw operations should be fast to prevent flicker.
Here's how we are meeting each of these challenges.
1. Data Structures
When the film-finder starts, it reads film data from a text file, and stores all the
attributes in separate linear arrays. The initial data is not sorted by any attribute.
Sorting the data using an attribute, say the film's title, would render operations
like alphabetical actor-search difficult, so instead the indices are sorted. This way,
the data's indices can be sorted for each attribute.
The existing FilmFinder followed a brute-force approach to finding the display films -
when it got a signal to zoom, it would scan the entire array of 1750 films and do four
comparisons on each element - whether the element lay between the x-axis (year) bounds
and within the y-axis popularity bounds. If it did, its new size and location were
calculated; it it did not, it's location was set off-screen.
After the erase routine drew the existing rectanges in the background color, the
redraw routine would scan the entire list of 1750 films again to find if their
locations lay within the visible screen, and draw them if they did.
We thought of a host of improvements and alternate strategies that would speed up the
data access capability. At the outset we decided against changing the existing
linear-array representation of the film data, as that would bias the representation
in favor of the two display attributes (year and popularity), to the detriment of the
other attributes.
From the simplest improvements to the most technically involved, here's what we
thought of.
- Perform optimizations of calculations that are done in the draw and
calculate loops.
- When calculating the new view, store the index of each visible rectangle in a
separate array, and while redrawing the image, use that array instead of
doing a search on the large array of 1750 films. This strategy is most effective
when the number of films being displayed is small - upto 200.
- If the either of the x-axis or y-axis (popularity or years) ranges is reduced,
the new display will be a subset of the old one - so use this information to calculate
the new array of film indices. Again, this method is efficient only if the number of
rectangles is about half the total films, since it entails another indirection.
- A more sophisticated scheme can eliminate range comparisons entirely at the
expense of three indirections by using a 2-dimensional array of size
popularity x #of years i.e. 10 x (1995-1920) = 10 x 75. So a cell at
position [8, 75] would correspond to a film made in 1995 with popularity 8.
The trouble with this approach is that a cell can contain none, one or many items,
so each location will have to have an overflow space. Besides, the matrix itself will
be sparse. At first, this seemed a promising approach, as it
eliminated comparisons entirely, but the boggling number of indirections
slowed down the zooming to such an extent that this approach had to be trashed.
Status
At this point, we have implemented #2, and are moving toward the implementation of #3,
and simultaneously trying to come up with novel approaches. Essentialy, then, the
tradeoff among the different data access methods is between the number of comparisons
and the number of indirections. This software is programmed using the
platform-independent user-interface builder 'Galaxy', which has advanced features
for manipulating lists. We have refrained from moving to #3 until we
get a good grasp on using those structures - we don't want to implement the
stuff using ordinary arrays.
The Lists and B-Trees available in Galaxy are faster than arrays or trees written in C,
so the emphasis is on using those.
2. Frequency of Updates
The x-axis has a granularity of 75, while the Y-axis has just 10 discrete points,
so the zooming along the Y-axis is not smooth at all. We have to work on calculating
intermediate points along the y-axis to smooth the operation.
3. Flicker-Free Operation
Galaxy has provided some software to do flicker-free picture dragging using off-screen
buffering; we have yet to incorporate it. This method uses the underlying data
structures, and unless we change those or develop a consistent interface to them,
it would be not be productive to go along.
Conclusion
Zooming is now smmoth and flicker-free when the number of data items is small (less
than 50);
we have to quantify the number as a benchmark for future comparisons. When the number
of visible data items is less, smooth zooming is determined by the data access
technique; when the number of items is large, it is limited by the rendering strategy.
Acknowledgements
Thanks are due to Dr.
Ben Shneidermanfor setting the goals of this project. The
comments and criticisms of Greg Baratoff and Claudio Esperanca are acknowledged.
Since this project is going to continue at least till the end of this month, Greg's
and Claudio's suggestions are going to be of great use.
References
- Ahlberg, C and Shneiderman, B. 'Visual Information Seeking: Tight Coupling of
Dynamic Query Filters with Starfield Displays', CAR-TR-638, Sep 1993.
- Galaxy Reference Manuals
- Galaxy Newsletter Sep 1993.